AIエンジニアとは?仕事内容・必要スキル・年収・なり方を完全解説

CONTENTS
「AIエンジニアになるには何が必要なのか」「実際の仕事内容は何か」「未経験からでも目指せるのか」——この記事を読んでいるあなたも、こうした疑問を持っているのではないでしょうか。
AIエンジニアは今、日本でも世界でも最も需要が高いITエンジニア職種のひとつです。ChatGPTをはじめとする生成AIの急速な普及により、企業のAI活用ニーズは爆発的に増加し、機械学習・深層学習を実装・運用できる人材の不足は年々深刻化しています。
しかし「AIエンジニア」という言葉は定義が曖昧で、求人によって求められるスキルや役割が大きく異なります。「データサイエンティストとの違いは?」「MLOpsエンジニアとは何が違うの?」といった混乱も多いのが現実です。
|
【この記事でわかること】
|
AIエンジニアとは何か?定義と役割を正確に理解する
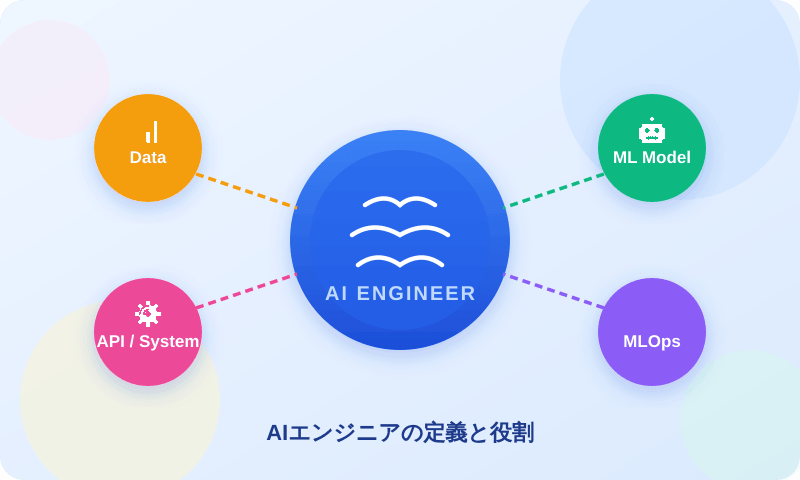
AIエンジニアの定義
AIエンジニアとは、機械学習・深層学習などの技術を用いてAIモデルを構築し、それをプロダクトや業務システムに組み込んで実際の価値を生み出すエンジニア職種です。
重要なのは「AIを作る人」という側面だけではありません。現代のAIエンジニアに求められるのは、「AIを使える形にして運用し、継続的に成果に結びつける人」としての役割です。
具体的には、以下の全工程に責任を持ちます:
- ビジネス課題に対してAIをどう適用するかの判断
- 学習用データの収集・整備
- 評価指標の設計とモデル開発
- プロダクトへの組み込みとシステム実装
- 本番環境での安定稼働と継続的な改善
AIはデータが変われば性能が変わり、同じ入力に対しても確率的に異なる挙動をすることがあります。そのため「仕様書通りに作れば完了」というソフトウェア開発の常識が通用しません。評価と改善のサイクルを回しながら「使える状態」を維持することが、AIエンジニアの本質的な仕事です。
AIエンジニア・データサイエンティスト・MLOpsエンジニアの違い
混同されやすい類似職種との違いを整理しておきましょう。
|
職種 |
主な役割 |
強みとする領域 |
|
AIエンジニア |
AIモデルの開発〜システム実装・運用まで一貫して担当 |
実装力・エンジニアリング・本番運用 |
|
データサイエンティスト |
データ分析・統計モデリング・インサイト抽出 |
統計・分析・ビジネス仮説検証 |
|
MLOpsエンジニア |
ML基盤の構築・CI/CD・再学習パイプラインの自動化 |
インフラ・自動化・運用効率化 |
|
リサーチエンジニア |
新アルゴリズムの研究・論文実装・性能限界の追求 |
学術研究・新手法開発 |
従来のITエンジニアとAIエンジニアの根本的な違い
従来のソフトウェア開発は「要件が決まれば、それ通りに動くものを作る」という決定論的なアプローチが基本です。一方、AI開発には以下のような本質的な違いがあります。
- 出力が確率的:同じ入力でも異なる結果になりうる
- データ依存:データ品質や量で性能が左右される
- 評価が多次元:精度・再現率・誤検知率・推論速度・コストなどのトレードオフ管理が必要
- 継続的劣化:本番環境でのデータドリフトにより性能が低下していく
- PoC-本番ギャップ:実験では動いても本番で崩れるケースが多い
AIエンジニアの仕事内容:5つのフェーズで完全理解
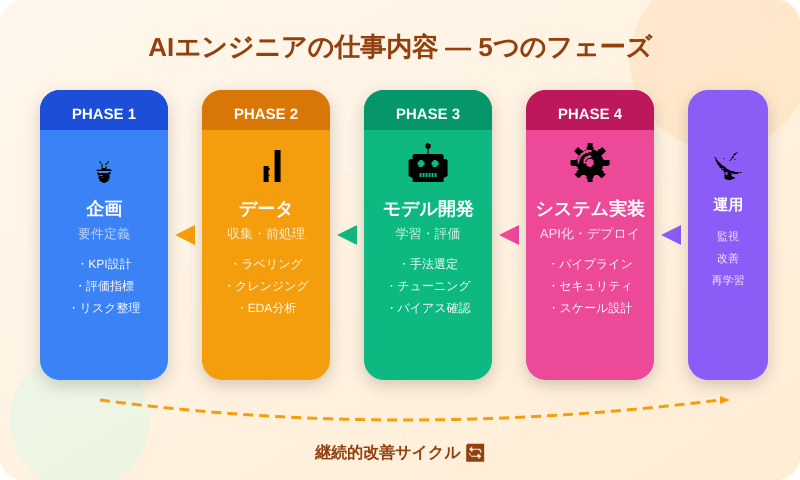
AI開発は「モデルを作って終わり」ではありません。価値を生むには、企画からデータ整備、モデル開発、システム実装、運用改善まで一連のサイクルで進めることが必要です。実務で時間の大半を占めるのは、モデル学習よりも周辺工程であることが多いです。
① 企画・要件定義:「何を解くか」を定める最重要フェーズ
最初に行うのは「AIで何を解くのか」の明確化です。同じ「需要予測」でも、在庫削減が目的なのか欠品防止が目的なのかで、評価指標も運用優先順位も大きく変わります。
要件定義で押さえるべき主なポイント:
- KPIと評価指標のセット設計(精度だけでなく再現率・誤検知コストも含む)
- 推論速度・クラウドコストの上限設定
- データ入手可否と品質の事前確認
- 法務・倫理・セキュリティリスクの洗い出し
- PoCと本番の差分(運用体制・監視・再学習・障害対応)の言語化
- ROIの見積もりと合格ラインの合意
② データ収集・前処理・EDA:AIの性能を左右する勝負どころ
「AIの性能はモデルよりデータで決まる」とよく言われますが、現場ではまさにその通りです。ここが最も時間を要し、かつ成果に最も直結するフェーズです。
データ整備の主な作業:
- ログ・DB・外部データなど収集経路の整備と利用許諾確認
- ラベリング基準書の作成とラベル品質のばらつき測定・改善
- 欠損・重複・外れ値・表記揺れのクレンジング
- 探索的データ分析(EDA):目的変数の偏り・季節性・データ分布の歪みの確認
- リークしそうな特徴量の特定と除外
- 学習・検証・テスト分割の設計(時系列かランダムかで評価の意味が変わる)
③ AIモデル開発・学習・評価:「高度な手法」より「再現性ある改善」
課題に応じて教師あり学習・教師なし学習・強化学習・深層学習などの手法を選択します。重要なのは「高度な手法を使うこと」ではなく、データ量・要件・運用制約に対して最も再現性高く成果が出る選択をすることです。
モデル開発の流れ:
- ベースラインの構築(まず動くものを作り、改善の根拠を積み上げる)
- ハイパーパラメータ調整と交差検証
- 混同行列・AUC・RMSE等で誤り方を多角的に分析
- 過学習・データリークの検証(未来情報が混入していないか)
- 属性バイアスと公平性の確認
- 再現性の担保(同条件で同結果が出るか)
|
⚠️ データリークに要注意 未来情報を含む特徴量が混ざると、検証環境では高精度に見えても本番で崩れます。 特に時系列データでは、学習データに評価時点以降の情報が混入するリークが起きやすいです。 |
④ システム設計・実装:モデルを「動くシステム」に変える
モデル単体では価値を生みません。推論APIとして提供するのか、バッチ処理で定期実行するのかを決め、以下を設計します:
- 入出力仕様・エラー処理・タイムアウト・スケール設計
- 学習から推論までのパイプライン構築
- モデルのバージョン管理と追跡(いつ・どのモデルが使われたか)
- セキュリティ設計(個人情報・認証・監査ログ)
⑤ 運用・監視・継続改善:本番で価値を維持し続ける
リリースがゴールではありません。AIは本番環境でデータドリフトにより性能が劣化していきます。安定稼働と改善を継続するために必要な体制:
- 精度劣化・データドリフトの検知アラート設定
- 遅延・コスト・エラー率の監視ダッシュボード
- 再学習パイプラインとロールバック体制
- A/Bテストによる改善効果の定量測定
- 生成AI活用時のガードレール・レビュー工程・監査ログの整備
AIエンジニアに求められる必須スキルと学習優先度

AIエンジニアに必要なスキルは、機械学習の知識だけではありません。データ、ソフトウェアエンジニアリング、インフラ、業務理解まで横断的なスキルセットが求められます。
スキル① Pythonと周辺ライブラリの実装力(最優先)
AIエンジニアの主力言語はPythonです。ただし「コードが書けること」で止まらず、以下の範囲まで実装できることが実務の水準です:
- データ加工:pandas・NumPy・PySpark
- 機械学習:scikit-learn・LightGBM・XGBoost
- 深層学習:PyTorch・TensorFlow・Hugging Face Transformers
- 可視化:matplotlib・seaborn・Plotly
- API化:FastAPI・Flask
- テスト・品質管理:pytest・型アノテーション・ログ設計
スキル② SQL・データ基盤(必須級)
「必要なデータを自力で取りに行けるか」が開発速度を大きく左右します。SQLは必須スキルです。加えて、データウェアハウス(BigQuery・Redshift)やETLパイプライン、データレイク設計の知識があると、データエンジニアと連携する際の解像度が上がります。
スキル③ 機械学習・統計の理論的理解
手法を暗記するよりも、「評価指標をどう選ぶか」「誤りをどう分析するか」「どこを直すと効くか」を説明できることが重要です。
優先して押さえるべき知識:
- 統計基礎:平均・分散・確率分布・仮説検定・信頼区間
- 線形代数:ベクトル・行列演算・固有値分解(深層学習理解に直結)
- ML理論:過学習・正則化・バイアス-バリアンストレードオフ
- 評価指標:混同行列・AUC-ROC・F1スコア・RMSE・BLEU・ROUGE等
スキル④ クラウド・インフラ・MLOps(差がつくスキル)
PoCで止まらず本番で価値を出せるかどうかは、ここで決まります。
- クラウドサービス:AWS(SageMaker・Lambda)・GCP(Vertex AI)・Azure ML
- コンテナ:Docker・Kubernetes
- CI/CD:GitHub Actions・Jenkins
- 実験管理:MLflow・Weights & Biases
- 監視:Prometheus・Grafana・CloudWatch
スキル⑤ 業務理解・コミュニケーション力(成果を決める根本)
AIは万能ではありません。ビジネス課題を「解ける課題」に落とし込む力、ステークホルダーと評価指標を合意する力、技術的限界を分かりやすく説明する力が、最終的な成果を左右します。「精度が上がった」だけでなく「KPIにどう効いたか」を語れるエンジニアが評価されます。
AIエンジニアの年収相場:日本・海外の実態
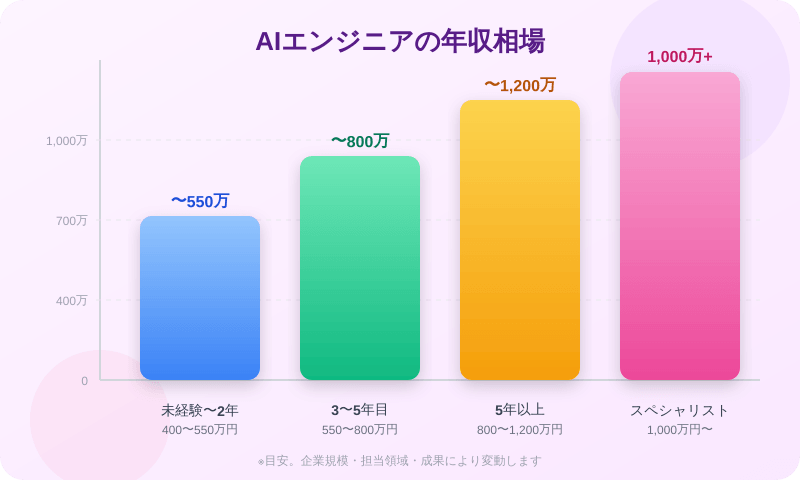
日本の年収相場
AIエンジニアの年収は、経験・スキル・担当領域によって大きく幅があります。参考として:
- 未経験〜2年目:400〜550万円
- 3〜5年目(実務で本番運用経験あり):550〜800万円
- 5年以上(MLOps・アーキテクチャ設計まで担当):800〜1,200万円以上
- スタートアップのAIリード・研究職:1,000万円以上も
経済産業省や各調査会社のIT人材レポートでも、AI・機械学習系エンジニアは他エンジニア職種と比較して高い報酬水準が示されています。
参考:経済産業省「IT人材需給に関する調査」(https://www.meti.go.jp/policy/it_policy/jinzai/)
年収を大きく左右する要因
最も重要なのは「できることの範囲」です。
- モデル作成のみ:相対的に年収の上昇が緩やか
- データ基盤・API化・クラウド運用まで一気通貫でできる:評価が高く年収上昇しやすい
- ビジネス成果(KPI改善・コスト削減)を定量的に説明できる:転職・昇給で有利
- 英語対応・海外チームとの協業経験:選択肢が大幅に広がる
海外(米国)との比較
Glassdoor・Levels.fyiなどの統計では、米国のAI/MLエンジニアの平均年収は15〜25万ドル(約2,200〜3,700万円)に達します。グローバル市場を意識したスキルアップは、長期的なキャリアオプションを広げる有力な選択肢です。
AIエンジニアの将来性:「いらない」論の真実と市場価値の行方
「AIエンジニアはいらない」と言われる背景
生成AIやAutoMLの普及により「AIがAIエンジニアを代替するのでは」という声があります。確かに、コード生成ツールの発達により定型的な実装作業の自動化は進んでいます。では本当に不要になるのでしょうか?
現実:役割が「消える」のではなく「変わる」
むしろ、AIツールの普及は「品質を保証する仕事の重要性」を高めています。
AIが生成したコードやモデルをそのまま本番環境に投入すると:
- 低品質な実装・脆弱性の混入リスク
- データリーク・偏り(バイアス)の見落とし
- 本番での予期しない誤動作
- 説明可能性・法的コンプライアンスの欠如
これらを判断・テスト・監視・修正できる人間の役割は、むしろ増大します。
将来性が高い領域
今後特に価値が高まるのは以下の領域です:
- ビジネス課題の設定力(何を解くべきかを判断する)
- データの責任ある取り扱い(プライバシー・著作権・倫理)
- 運用での劣化検知・再学習・ガードレール設計
- 生成AIを安全に組み込む技術(RAG・ファインチューニング・プロンプトエンジニアリング)
- AI出力の品質保証とリスクマネジメント
焦点は「コードを書く人」から「不確実なAIを安全に動かし、成果に結びつける人」へ移っています。AIツールを使いこなしながら、判断と設計で価値を出せる人ほど市場価値が上がる時代です。
AIエンジニアになるには:未経験からの学習ロードマップ
ステップ1:プログラミング基礎とデータ操作(1〜3ヶ月)
まず最初にやるべきこと:
- Python基礎(変数・関数・クラス・ライブラリのimport)
- pandasとNumPyでのデータ加工・集計
- SQL基礎(SELECT・JOIN・GROUP BY・ウィンドウ関数)
- Jupyter Notebookの使い方と可視化(matplotlib・seaborn)
参考学習リソース:
Python公式ドキュメント(https://docs.python.org/ja/)
Kaggle Learn(https://www.kaggle.com/learn)
ステップ2:機械学習の基礎実装(2〜4ヶ月)
scikit-learnを使い、実データで以下の型を身につけます:
- 回帰・分類・クラスタリングの基本実装
- 評価指標の選択と解釈(混同行列・AUC・MSE等)
- 交差検証・ハイパーパラメータチューニング
- 特徴量エンジニアリングと選択
Kaggleのコンペ参加が実力向上に最も効果的です。まずは「入門コンペ」(Titanicなど)から始め、カーネル(解説ノートブック)を読むことで実務的な手法を学べます。
ステップ3:深層学習とNLP・画像処理(2〜4ヶ月)
- PyTorchの基礎(テンソル・自動微分・ニューラルネット実装)
- CNN(画像分類)・RNN/Transformer(テキスト処理)の理解
- Hugging FaceでのBERT・GPT系モデルの利用
- ファインチューニングの実施
参考:fast.ai(https://www.fast.ai/)は実践的な深層学習を学ぶのに優れた無料リソースです。
ステップ4:MLOps・本番化・クラウド(2〜3ヶ月)
- Dockerでのコンテナ化
- FastAPIでのモデルAPI化
- AWS・GCP・Azureのいずれかでのデプロイ
- MLflowでの実験管理
- GitHub Actionsを使ったCI/CDパイプライン
AWSの「AWS Certified Machine Learning - Specialty」やGCPの「Professional Machine Learning Engineer」資格は、クラウド上でのAI実装力の証明になります。
参考:https://aws.amazon.com/jp/certification/certified-machine-learning-specialty/
ステップ5:ポートフォリオの構築(並行して実施)
転職・案件獲得では「資格」より「成果物」が効きます。以下の要素を含むポートフォリオプロジェクトを1〜2本作ることを目標にしてください:
- 実際のデータを使った課題設定と前処理
- モデルの学習・評価・改善の記録(実験管理ツールで記録)
- FastAPIでのAPI化とDockerコンテナ化
- クラウドへのデプロイと監視の仕組み
- README・技術ブログでの手順・考察の公開
おすすめ資格:G検定・E資格・クラウドAI資格
AIエンジニアに資格は必須ではありませんが、特に未経験の場合は「何をどこまで学んだか」を第三者基準で示す手段として有効です。
- G検定(JDLA Deep Learning for GENERAL):AIの概要・倫理・活用事例を幅広くカバー。非エンジニア含め共通言語づくりに有効。
- E資格(JDLA Deep Learning for ENGINEER):深層学習の理論・実装を問う。合格者はエンジニアとしての実力を示せる。
- AWS Certified Machine Learning – Specialty:AWSでのMLシステム設計・実装の理解を証明。
- Google Cloud Professional ML Engineer:GCPでのML運用・設計力を証明。
資格取得は目的ではなく手段。「動く成果物+資格のセット」で転職活動に臨むのが最も効果的な戦略です。
AIエンジニアのキャリアパス:専門深化から横展開まで
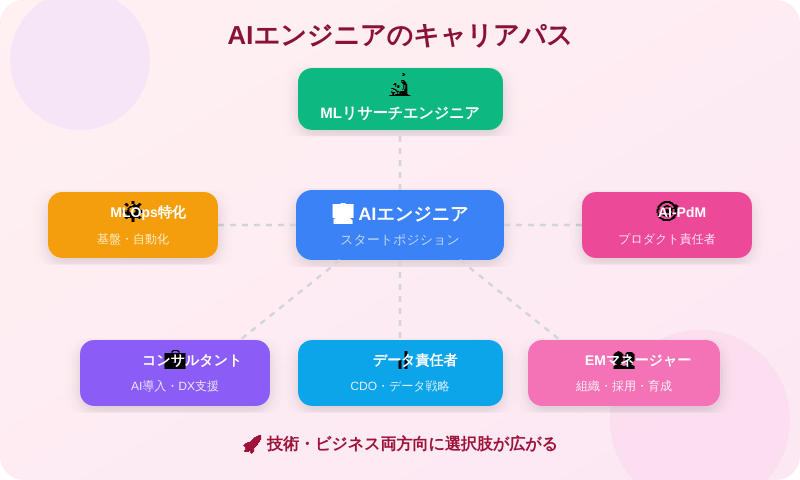
専門を深める方向
- MLリサーチエンジニア:新アルゴリズムの研究・論文実装・最先端手法の導入
- シニアMLエンジニア:大規模モデル開発・アーキテクチャ設計・チームのテクニカルリード
- MLOpsエンジニア:学習・推論パイプラインの自動化・プラットフォーム構築
- AIセキュリティエンジニア:敵対的攻撃・プロンプトインジェクション・安全なAI実装
横展開する方向
- AIプロダクトマネージャー(PdM):AIを活用するプロダクトの企画・ロードマップ設計
- データ責任者(Chief Data Officer):企業全体のデータ戦略策定
- AIコンサルタント:企業のDX・AI導入支援
- エンジニアリングマネージャー:AIチームのマネジメント・採用・組織設計
キャリアアップの共通原則:「成果の言語化」
どのキャリアパスを歩む場合も、成果を定量的に言語化できることが市場価値を高めます。「精度が2%上がった」より「誤検知率を30%削減し、審査工数を月間100時間削減した」という形で、ビジネスインパクトを語れることが転職・昇進での強い武器になります。
AIエンジニアが活躍する分野と具体的な活用事例
製造業:外観検査・故障予知
画像認識AIによる製品の外観検査自動化や、センサーデータを用いた設備の故障予知は、製造業での代表的な活用事例です。精度だけでなく、照明条件の変化やセンサー劣化に耐える運用設計が成果を左右します。
金融:不正検知・与信スコアリング
誤判定コストが非常に高い領域です。「なぜそう判断したか」を説明できる解釈可能なモデル設計と、監査対応が求められます。XAI(説明可能なAI)への関心が高まっている領域でもあります。
医療・ヘルスケア:画像診断支援・創薬
医療画像(CTスキャン・X線)のAI診断支援は実用化が進んでいます。個人情報保護・医療規制への対応、および臨床医との連携設計が重要です。
小売・ECサービス:レコメンド・需要予測・チャットボット
購買データをもとにしたパーソナライズドレコメンド、需要予測による在庫最適化、カスタマーサポートへのLLM活用が進んでいます。生成AIを組み込む際は、誤情報・ポリシー違反のリスクを織り込んだガードレール設計が不可欠です。
自動車・モビリティ:自動運転・画像処理
自動運転技術は画像・LiDAR・センサーフュージョンなど複数の技術を統合する高度なAI開発領域です。機能安全規格(ISO 26262)への対応など、高い品質保証水準が求められます。
AIエンジニアに向いている人の特徴
以下の特性を持つ方は、AIエンジニアとして成果を出しやすい傾向があります:
- 仮説を立てて検証することが苦にならない:AIは一発で正解に到達しにくく、改善を積み上げる仕事。試行錯誤を楽しめる人が向いています。
- データと向き合う粘り強さがある:地味な前処理・ラベル整備が結果を大きく左右します。丁寧に進められる人が強い。
- 変化に適応し学び続ける意欲がある:ツール・フレームワークの進化が速いため、特定技術への依存より「課題解決力」を磨く姿勢が重要。
- ビジネス課題への関心がある:技術だけでなく「それが事業にどう効くか」を常に意識できる人が長期的に価値を出せます。
- コミュニケーションを大切にする:AIは関係者との合意なく現場に根付かない。説明・調整・合意形成が得意な人は有利。
まとめ:AIエンジニアへの道と次のステップ
この記事では、AIエンジニアの定義から仕事内容・スキル・年収・なり方まで体系的に解説しました。最後に要点を整理します。
|
【この記事の要点まとめ】
|
次にやるべきこと
この記事の内容を理解した読者は、まず以下から始めてください:
- Kaggle LearnでPythonとMLの基礎を無料で学ぶ
- Kaggleの入門コンペ(Titanic・House Prices)に参加し、実データで実装する
- GitHubにポートフォリオリポジトリを作り、学習記録を公開する
- G検定またはE資格の取得を検討し、学習の指針を設定する
AIエンジニアとして、本番で価値を出し続けたい方へ
ここまで読んでいただいた方は、AIを「本当に使えるもの」にすることへの強い関心をお持ちだと思います。精度を上げることだけでなく、実際のビジネス課題に対してAIをどう設計し、安定稼働させ、改善し続けるか——そこに面白さを感じる方と一緒に働きたいと思っています。
私たちのチームは、PoCを本番に持ち込み、事業に根付かせることを最も大切にしています。技術的な深さと、ビジネス感覚の両方を磨ける環境を用意しています。
もし「こういう仕事がしたかった」と感じていただけたなら、ぜひ一度、私たちの採用ページを覗いてみてください。あなたのキャリアの次のステップを、一緒に考えられれば嬉しいです。
AIエンジニアを目指している方へ
本記事ではAIエンジニアの仕事内容・スキル・なり方についてお伝えしましたが、
「自分も実際にエンジニアとして働いてみたい」と感じた方も多いのではないでしょうか。
未経験からエンジニアになるためには、
- 実務を見据えたカリキュラムで基礎を固められるか
- 現場に入ってからもサポートしてもらえる環境があるか
を意識して会社を選ぶことで、入社後の成長スピードが大きく変わります。
そうした「入社後も安心して成長できる環境」を探している方には、
未経験者の育成に力を入れたSES企業 ZeroCode PLUS という選択肢もあります。
- エンジニアスキルを体系的に学べる
- 未経験者でも実務を意識したカリキュラムで基礎から丁寧にサポート
- 研修から現場アサインまで一貫したフォロー体制
- 完全オンライン対応でスキマ時間を活用した学習が可能
※話を聞くだけ・内容を確認するだけでも大歓迎です




